4 Steps
To Harmonize Data
Turn complex, multi-source Alzheimer’s disease datasets into a single harmonized dataset ready for clinical research and AI-driven tools like MINT-AD.

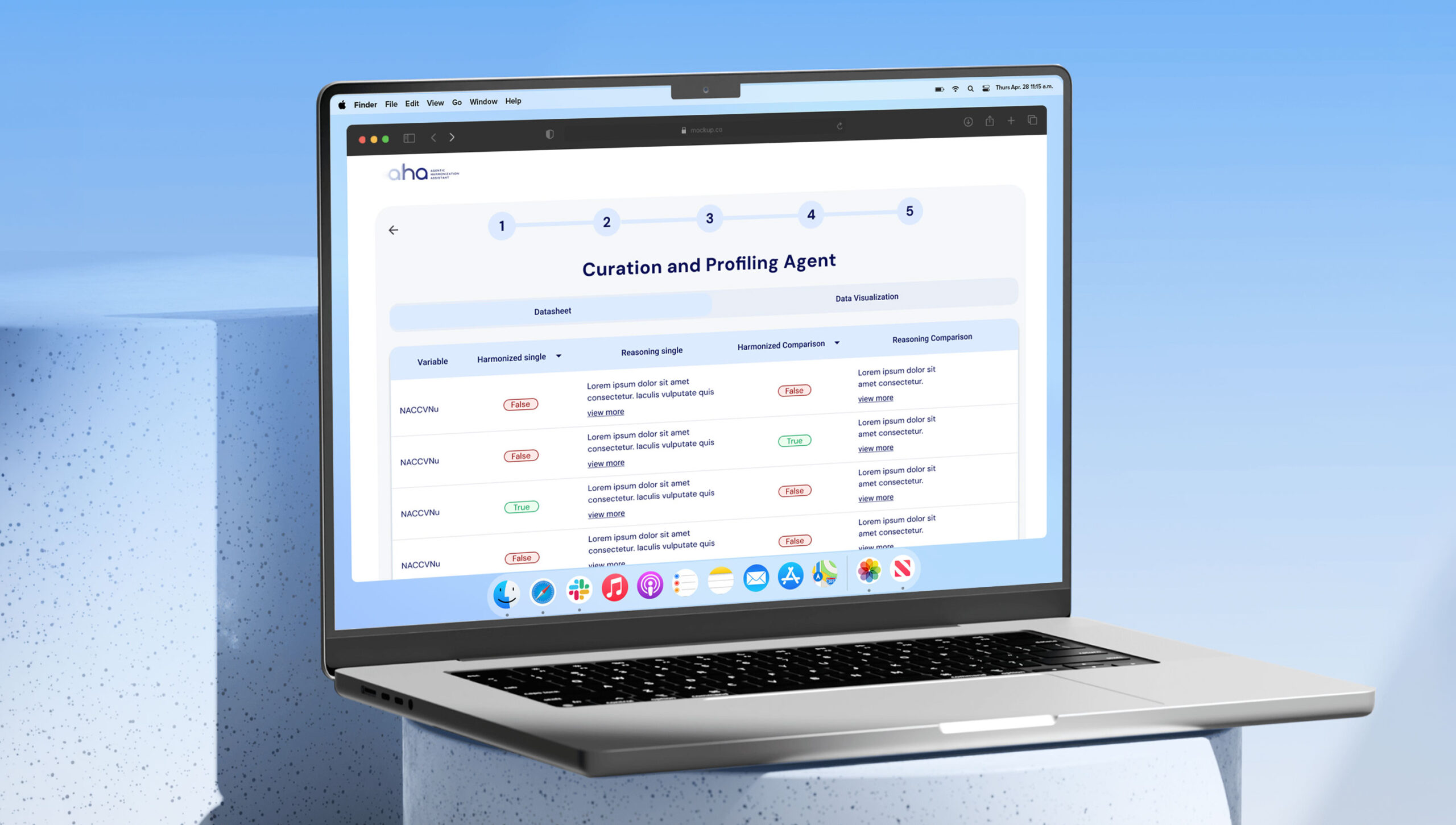
Profiling
aha™ automatically profiles both standard and raw datasets, reading their data dictionaries to understand variable types, distributions, and clinical meaning. This process creates a rich, machine-readable description for every variable.
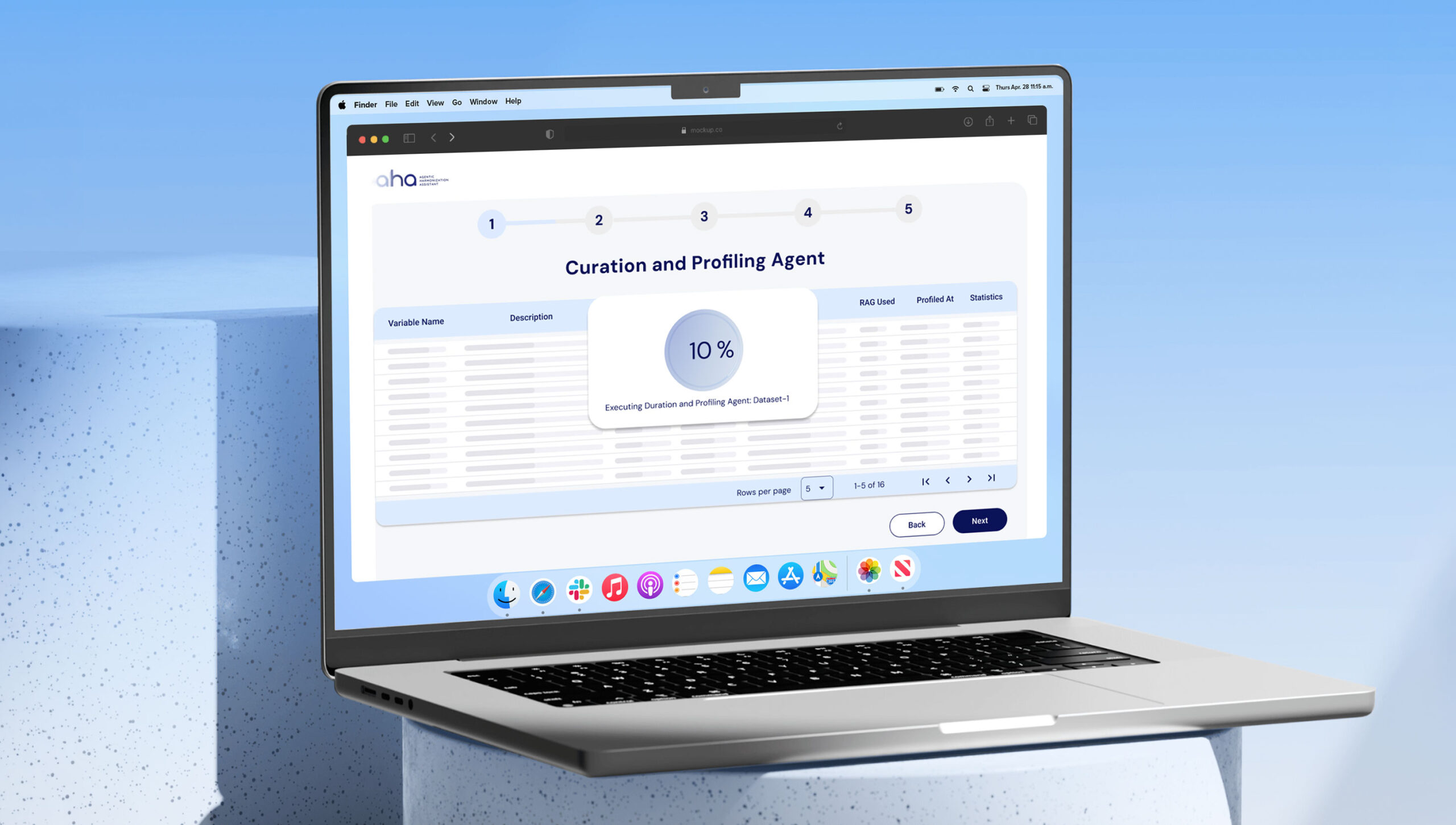
Strategy & Planning
Collaborative agents design a harmonization plan for each variable, proposing mappings, transformation steps, confidence scores, and approval flags. These plans are iteratively refined through a proposer–critic–refiner workflow before execution.
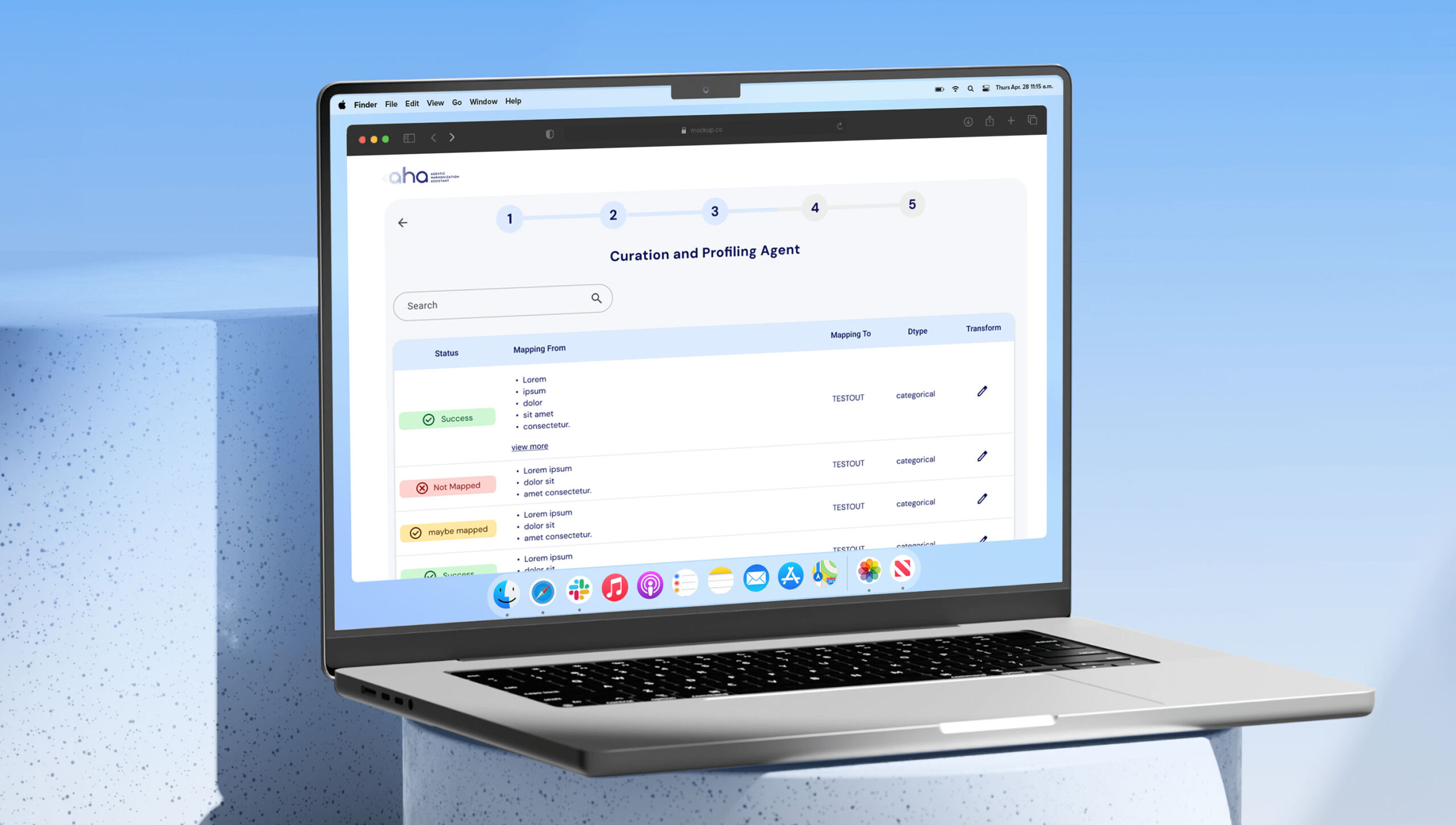
Execution
Once the plan is approved, aha™ applies a library of transformations to harmonize the data. These transformations include recoding values, aligning formats, merging columns, and standardizing text to generate a dataset that follows the selected harmonization standard.
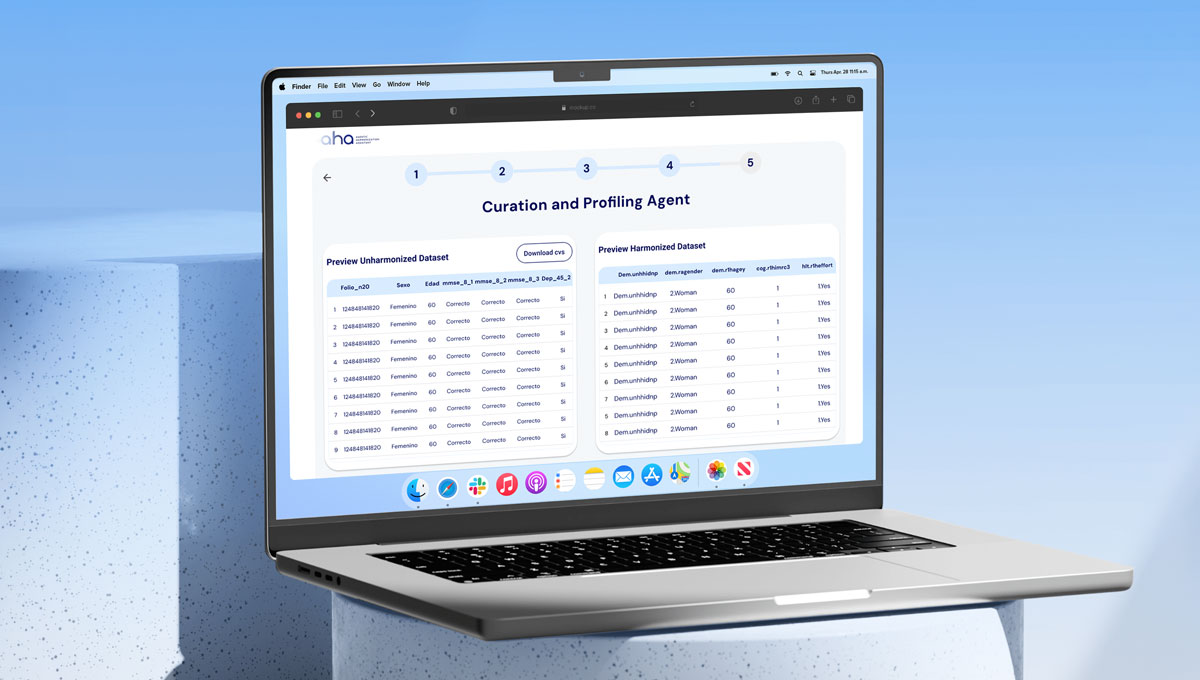
Validation
Compares the harmonized dataset against the defined standard and the original source profiles, computing summary statistics and verifying each planned transformation. The system flags discrepancies and generates per-variable validation tables, ensuring the final dataset is transparent, traceable, and ready for high-stakes AI modeling.